Since the early 2000s the deep generative approach has grown rapidly with a wide number
of generative models. The most famous deep generative models are the Generative
Adversarial Network (GAN), the Auto-Regressive model (AR) and the Variational Autoencoder
(VAE).
During my MSc in Artificial Intelligence, I had the opportunity of studying and developing from scratch a Conditional VAE, which we trained on CelebA dataset (a large-scale face attributes dataset with more than 200K celebrity images, each with 40 attribute annotations).
Let’s first briefly describe this amazing Deep Learning model and let’s then explore its ability with some experiments.
Here you can find the repository of this project.
What is a CVAE?
This is only a brief introduction to the VAEs world.
If you’re interested in a more detailed reading, let’s have a look to our project work report at the end of this page.
Let’s start by defining what a Variational Autoencoder (VAE) actually is.
A VAE is made of an encoder (or inference network – usually a CNN) and a decoder (or generative network – again usually a CNN). This two neural networks work together on a target latent variable model (LVM), that is a probability distributions over two sets of variables, defined as
p(x,z) = p(x|z) p(z)
where x is the observed variable and z is the latent variable (i.e. never observed) [1].
The Conditional Variational Autoencoder (CVAE) is an extension of VAE developed in the field of Neural Machine Translation (NMT) [2].
The key idea is to assume that our model is conditioned not only on x, but also on an observable y, which guides the translation process. With this assumption, the target LVM becomes
p(x,z,y) =p(x|z,y) p(z|y)
From the NMT field, the CVAEs were extent to other AI applications, such as the Conditional Image Generation, which aim is to generate realistic images with particular features. A CVAE used for this purpose works on a LVM where
- x is the original image, seen as a matrix of pixel intensities;
- y is the label of a given image, which encodes the image features;
- z is the latent vector, our unobserved variable.
We implemented a β–CVAE [3] from scratch using Tensorflow 2.2 and we trained it on CelebA dataset.
Recalling the LVM p(x,z,y) previously mentioned, we can easily see that in our application:
- the observed variables x are the CelebA RGB images, properly cropped and normalized to ignore the background;
- the guiding variables y are the 40-dimensional binary vectors which encode the presence (0) or absence (1) of a given face attribute in the images;
- the latent variable z belongs to a 128-dimensional space (latent_dim = 128).
Here is a schema of our CVAE:
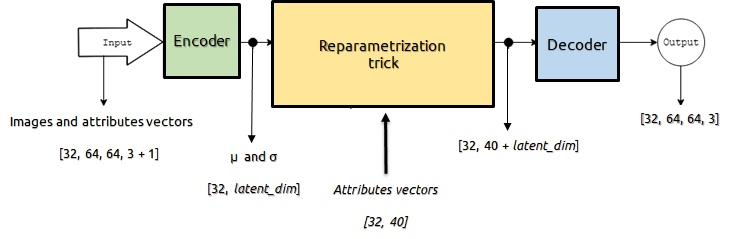
We trained our model with batches of 32 RGB imges to which we had added the attributes vectors as the 4-th channel. We used Adam optimezer [4] to minimize the objective function described in the report (equation (8)).
Conditional Image Generation
Usually, when we work with CVAE we suppose that our data (in our case, the CelebA images) are normally distributed. Thus, we can sample the latent space of our generative model by simply sampling a Normal distribution.
Starting from a sampled latent vector z, we can generate new faces (i.e. that do not exist in CelebA dataset) with specific attributes by decoding z, properly conditioned with the desired attributes vector.
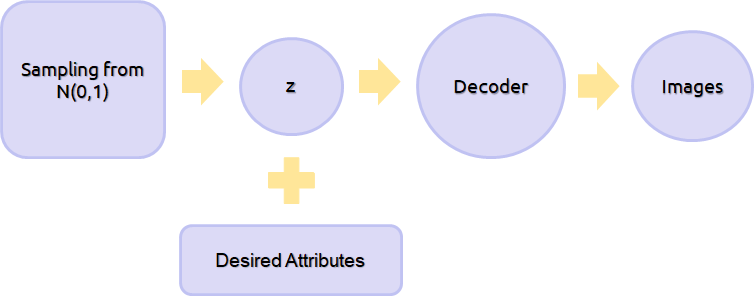
Here are some examples of conditional generated images with specific attributes (listed on the side):


Vectors Interpolation
Generative models have the ability to interpolate real samples to generate non-existent manipulated samples. The interpolation simply consists in performing linear algebra in the latent space learned by the generative model.
Let’s consider two images A and B and their latent mean vectors extracted using the pre-trained generative model.
To generate new samples we simply move linearly along the interpolation vector
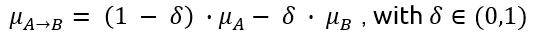
and then we inject the resulting vectors into our generative model. By decoding these latent vecors, we generate a set of new images which create a transition between the two original images.
Here are some examples of vector interpolations, the original images are the first and the last of each row:


N.B. none of the 6 images in the center of each row are part of CelebA dataset: they are definitely new faces!
Attributes Manipulation
As a further step in the exploration of our generative model abilities, we can reconstruct a batch of images with some new attributes.
To do so we simply need to:
- create a batch of images from the test set (the batch should be as heterogeneousas possible in order to test our network ability on input with different features);
- encode the images using the pre-trained model encoder and store the resulting mean vectors;
- specify the desired new attributes changing the original labels;
- decode the mean vectors, combined with the new attribute labels, using the pre-trained model decoder.
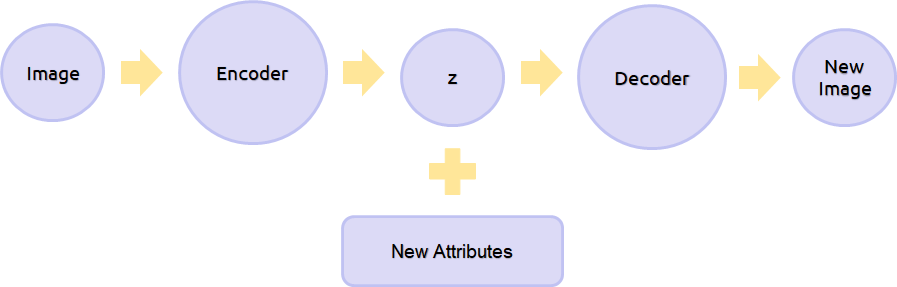
The result will be the original batch of images with the desired new attributes. For example, we can make them all smiling, or change their gender, or maybe making them wearing eyeglasses. There is no limit to our imagination, but there are inner limits to our generative model ability. Thus, the more balanced our model is, the more accurate will be the resulting new images.
Here are the original batch of images and the modified ones:




As you can see, not all the resulting images have the required attributes, and this is beacuse of the latent space distribution. Simply speaking, some images are encoded in the latent space in a more suitable position to get the desired attribute. For example, let’s look at Men with moustache image: those images which were originally men, are more likely to get a good moustache representation than the women’s images.
References
[1] Diederik P Kingma and Max Welling. Auto-encoding variational bayes, 2013
[2] Biao Zhang, Deyi Xiong, Jinsong Su, Hong Duan, and Min Zhang. Variational neural machine translation, 2016.
[3] Irina Higgins, Lo ̈ıc Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew MBotvinick, Shakir Mohamed, and Alexander Lerchner. beta-vae: Learning basic visualconcepts with a constrained variational framework, 2017.
[4] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2014.
This project is part of my Deep Learning exam of the Master’s degree in Artificial Intelligence, University of Bologna.
Here is our project work report: