Nowadays we’ve access to a huge amount of sources of information, but how can we efficiently filter them? How can we establish which articles are the most renowned ones? A possible solution comes from the graph theory.
For example, let’s consider the COVID-19 Open Research Dataset (CORD-19), prepared by a coalition of leading research groups in coordination with The White House Office of Science and Technology Policy in response to the COVID-19 pandemic. This growing dataset includes an archive with more than 180k scientific articles about COVID-19, SARS-CoV-2, and related coronaviruses.
To search for the most relevant pubblications in coronavirus literature, we can start by modelling the CORD-19 as a citation graph, that is a directed graph with the scientific articles as nodes and the citations as edges.

Starting from this network of citations we can search for the most relevant pubblications in the dataset by simply ranking the graph nodes under a few assumptions.
A simple approach: In-Degree Rank
A graph node has both an Out-Degree and an In-Degree, that are respectively the number of outcoming and incoming edges. In our graph, the In-Degree of a node is nothing more than the number of citations received by the corrisponding article. Thus, we can start exploring our database by ranking the articles according to their normalized In-Degree.
As first step, we define the edgesList, which contains all the pairs (nodeA, nodeB) where nodeB is a successor of nodeA. This list will be the algorithm input, which steps are described below:
- counting the number of incoming edges of each node (i.e. the In-Degree);
- normalizing each In-Degree by the total number of edges in the graph;
- sorting the resulting list of pairs (node, rank) in descending order with respect to rank.
According to In-Degree Rank, the three most relevant articles are:
| Title |
|---|
| “Isolation of a novel coronavirus from a man with pneumonia in Saudi Arabia” |
| “Identification of a novel coronavirus in patients with severe acute respiratory syndrome” |
| “A novel coronavirus associated with severe acute respiratory syndrome” |
PageRank
One of the most well known is the PageRank algorithm [1]. This algorithm was developed by Google at the end of the 90s to sort through hundreds of billions of webpages to find the most relevant and useful results.
The PageRank algorithm is based on the assumption that the relevance of a webpage depends on both the quantity and the quality of those webpages which link to it.
More formally, given a webpage pi and the set M(pi) of webpages which link to it, the rank of pi is computed as follows
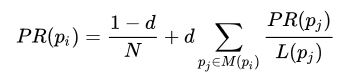
where N is the total number of webpages, d is the so called damping factor and L(pj) is the number of of outbound link of pj.
This kind of reasoning can be easily extended to our citation graph by assuming that the most renowed articles are more likely to receive citations from other articles. Therefore, if we call aj the j-th article, then the L(aj) term in the previous formula will refer to the number of articles mentioned by aj, that is the Out-Degree of the node aj of our citations graph.
The vicious circle of recursion
PageRank is an iterative algorithm which converges to the final ranks after a certain number of interations. This is clear by looking at it recursive definition: to compute the rank of a node, we need to know the rank of all its ancestors.
Any iterative algorithm needs a stopping condition, which directly affects the algorithm behaviour. Therefore, by defining two different stopping conditions, we can define two variants of PageRank:
- Max Iterations: the algorithm stops after having performed a pre-defined number of steps.
- Tolerance: the algorithm stops whenever two successive steps produce a variation in the ranks smaller than a given tolerance.
Algorithms implementation
We implemented both In-Degree Rank and PageRank using Scala and its Spark extension based on the Resilient Distributed Dataset (RDDs).
Here is the whole repository, and below you can find the direct links to the different algorithms implementations:
References
[1] Larry Page, Sergey Brin, Rajeev Motwani,Terry Winograd (1998), “The PageRank Citation Ranking: Bringing Order to the Web“.
This project is part of the Languages and algorithms for AI exam of the Master’s degree in Artificial Intelligence, University of Bologna.